It feels like it's been a while since I've written anything for the blog, the last post has been up since I did my Tildewhirl interview back in April and there's been nothing but silence here since then. That's not because I haven't wanted to post, I started working on capturing some tkts development, and I've had a couple of friends ask for tutorials on using iptables and packaging things. I'm really excited to get that feedback and write those posts, I just haven't been able to!
That begs the question, why not? Well the way that lambdacreate was designed initially was essentially me fumbling around with Lua and Lapis and just shoving everything that sort of worked into a docker container and calling it a day. The packages I relied on at the time weren't well maintained in Alpine, I really had no clue how to design a website let alone a somewhat dynamic web application, so I more or less hacked around these limitations using a bit of administrative magic and the result was the blog up until this point. It should look the same as before, but now we're way more functional! I no longer need to rebuild an x86_64 docker container just to post a new blog post, I can work solely with flat text files and lua and manage everything the old fashioned way. That's potentially what I should have done to begin with.
See the biggest issue with the design was the creation of the container itself, like the last post explained, most of my computer is done on an old armv7 system. It's took weak to build containers, even if they're not cross compiled, heck I tried to get qemu to run on the droid just for the heck of it and it couldn't even handle launching a VM in a reasonable time frame. The point is, that tooling is just too heavy for what I use day to day. Previously that meant digging out a different computer, like my Asus netbook which has a N4000 Celeron in it, just to make an already written post live. If I'm traveling that means everything grinds to a halt and there's no posts because I typically only bring my droid with me out and about. Major pain.
I guess what I'm trying to say is I de-over-engineered my blog, bye bye docker, hello old school administration! But that doesn't mean we've gone off the reserve and migrated to a static site generate, oh no, this is the same great Lua on Lapis dynamically generated content we started with, I'm just holding the tool correctly this time.
Redesigning the Site
If you're on mobile you'll probably need to scroll to the bottom of the page, otherwise I'm sure you noticed the changes on the right hand bar. I've added a number of new routes to the site to handle blog post, archiving, podcasts, and projects. Some of that is familiar, plenty of it is new, and some of it was supposed to work from the onset but it took me two years to properly implement. I'll let you click around and explore the changes to the site by yourself, lets talk about Lapis and how all of this works.
Routes in Lapis
In Lapis your web application is a collection of lua scripts that get executed by OpenResty. From a 1000ft view the core of that is a file called app.lua that Lapis loads with all of its various dependencies just like any lua runtime. Your routes leverage a Lapis internal called Lapis.Application which has an OO style implementation. All of this just means that your Lapis application is a collection of supporting lua libraries and app:function("route", "uri" function()) calls. Here's the index function for Lambdacreate, it'll make things clearer.
app:match("index", "/", function(self)
--Table of last 10 blog posts
self.archive = lcpost.getLast(10)
--The last published post
self.latest = lcpost.getPost(lcpost.getLatest())
--Last update of published post
self.timestamp = lcpost.getUpdated(lcpost.getLatest())
self.shows = lcpod.getShows()
--Table of projects
self.projects = lcproj.getArchive()
self.internal_layout = "index"
return { render = true, layout = "layout" }
end)
When you visit https://lambdacreate.com the Lapis application matches the HTTP request to the "index" route, which triggers a cascade of functions to internally gather information. Note the self variable here, the function that the route triggers has a self = {} var, that we attach named values to. These self variables are accessible inside of the etlua templating engine, which is what we use to do something with all of this information. These templates are part of the layout variable in the return call, we return the output of the route function to Lapis, which renders the layout template with the values from self. In Lambdacreate I use a global layout.etlua file, and then an internal_layout self variable to change the inner content.
This may make more sense if you look at the full template alongside the explanation, layout.etlua can be found here, and index.etlua can be found here.
Inside of layout.etlua we have a render function call that takes the value of the self.internal_layout and renders it's content. It essentially nests that etlua template into the layout.etlua template so the self variables are shared inside of that internally rendered template. Since self.internal_layout = "index", we render the body block of the website to the contents of the index template.
< render("views." .. internal_layout) >
That index.etlua file looks like this in full, you can see we're calling even more templates to render inside of that, but you get the gist. Anything inside of self is referential inside of etlua. I had to convert the HTML tags to paranthesis, because it kept breaking my etlua template rendering. Hopefully it's clear enoug.
(div class="row")
(div class="leftcolumn")
(div class="post")
(% render("views.posts." .. latest.id) %)
(/div)
(/div)
(div class="rightcolumn")
(div class="card")
(h3)Bio(/h3)
(% render("views.about") %)
(/div)
(div class="card")
(h3)Recent Posts:(/h3)
(ul class="list")
(% for k, v in pairs(archive) do %)
(% local route = "/posts/" .. v.id %)
(li)(a href="(%= build_url(route, { host = site, key = v.id }) %)")(%= v.title )(/)(/li)
(% end %)
(/ul)
(h3)(a href="(%= build_url('archive/post', { host = site }) )")Post Archive(/a)(/h3)
(/div)
(% render("views.shows") %)
(% render("views.dev") %)
(/div)
(/div)
What's really cool, is the Recent Posts segment, it's a lua function nested into the template itself. All it does is build a route by iterating over a table of information that gets passed by the self.archive variable. What this means is that the we only have to define the Recent Posts once as this function, every time we add a new post to the database the site will re-render the page the next time it's visited. No need to rebuild, reload, etc. Most of the templates that get rendered by layout or inside of index operate like this! We just need to know where to look.
Post/Podcast Generation
So now that you know a bit about the templates, you can probably guess that our blog posts (and podcast episodes!) are generated the same way, but where are we fetching all of this information from? Well previously we stored all of our post information in a file called posts.lua, and it was a big old lua table filled with keys and values. Things haven't changed too much from that design honestly, we're still passing all of the information needed to render a route to Lapis as a table, however we're storing and managing that information in an Sqlite3 database! Lets look at lcpost.getLast(10) in the index route.
--Return a table of the last X records
function lcpost.getLast(num)
local db = sql.open("lc.db")
local stmt = db:prepare("SELECT id,title FROM posts ORDER BY id DESC LIMIT :limit")
local info = {}
stmt:bind_names({limit = num})
for row in stmt:nrows() do
table.insert(info, row)
end
stmt:finalize()
return info
end
That seems straight forward right? We select the id and title from our posts table, sort the output, and limit it to whatever variable we pass to the function. Then for each row returned from the SELECT we insert the values into a table called info and return it. The table we get from the select looks like this, and is what we iterate over in our Recent Posts route generation.
{
{ id = 35, title = "Truly using Lapis"},
{ id = 34, title = "The Infamous Droid"},
}
There's more complexity here than just hand typing a lua table, but the exact same logic and generation code works despite that complexity. The ability to coerce values into tables means we can more or less store things however we desire.
That's pretty simple, etlua gives us an easy way to populate HTML wire-frames with dynamically changing data, and Lapis gives us a nice interface for passing that information inwards to the rendering service. This provides a really clean way of thinking about how the website works, based on the above you can infer that when your visit https://lambdacreate.com/post/1, that it does a SELECT from posts where id = 1; and then returns that table above to populate the template. Dead simple design.
For the podcasts and archival information it gets a little bit more complicated, but I think you'll agree that it's still just as easy to understand. Here lets look at /archive routing, since it touches on the complexity of /podcast routing too.
--Blog posts/Podcast episode archive lists
app:match("/archive/:type(/:show)", function(self)
if self.params.type == "post" then
--Table of all posts
self.archive = lcpost.getArchive()
self.timestamp = {}
self.internal_layout = "post_archive"
return { render = true, layout = "layout" }
elseif self.params.type == "podcast" then
--Specified show information
self.show = lcpod.getShow(self.params.show)
--Table of all episodes in the show
self.archive = lcpod.getArchive(self.params.show)
self.timestamp = {}
self.internal_layout = "podcast_archive"
return { render = true, layout = "layout" }
else
--Redirect to e404 if the archive type doesn't exist
return { redirect_to = self:url_for("404") }
end
end)
Just like out index route, we use app:match to check the url of an HTTP request. Here that match is a little fuzzy, it'll match any of the following correctly.
- https://lambdacreate.com/archive/post
- https://lambdacreate.com/archive/podcast/droidcast
- https://lambdacreate.com/archive/podcast/lambdacast
Neat! We have one function that's capable of routing archival information for blog posts, and two different podcasts! If you try and go to /archive/podcast or /archive/podcast/something-that-doesnt-exist, it'll also force route you to a 404 page, so technically there's a fourth route hidden in there too. All of this works by matching the values passed in the url via the self.params value.
In Lapis when you visit /archive/podcast/droidcast the values of the url are saved in self.params vars named as the values in the app:match(route) segment. So for the /archive function we have two named variables :type and :show. If you visits /archive/post, then self.params.types == "post", and for /archive/podcast/droidcast self.params.type == "podcast" and self.params.show == "droidcast". After that render is handled inside an if statement to direct the request to the right set of functions and render the correct templates.
More simply, you can visualize it like this.
https://lambdacreate.com/archive/podcast/droidcast
-> self.params = { route = "archive", type = "podcast", show = "droidcast" }
Building a Paste Service
Still with me? We're almost done, and if you're still reading then I think this is potentially the most interesting part of it all. To figure out how to get all of this to work correctly I've added a paste service to Lambdacreate. It's meant for internal use only (sorry!), but it has the most complicated route handling of anything else on the site.
I'm going to focus on the Lapis routing, if you're curious about the lcauth script you can find it here.For the purpose of discussing here, just know that it takes values passed via self.params and queries a database to determine if they exist, then returns true or false back to the Lapis application.
--Paste Service
--curl -v -F key="key" -F upload=@argtest.fnl https://lambdacreate.com/paste
app:match("paste", "/paste(/:file)", respond_to({
GET = function(self)
--This GET allows us to share the same name space as our POST
--static/paste - nginx:nginx 0755
--static/paste/file - nginx:nginx 0640
return
end,
POST = function(self)
--Check authorization of POST
local authn = lcauth.validate(self.params.key)
if authn == true then
--Upload a file to paste directory
local tmp = lcpaste.save(self.params.upload.content, self.params.upload.filename)
--Return the paste url
return {
render = false,
layout = false,
self:build_url({ host = config.site }) .. "/paste/" .. tmp .. "\n"
}
else
--Return access denied
return {
render = false,
layout = false,
"Access Denied\n"
}
end
end,
}))
For /paste we have both GET and POST handling, everything else we've discussed has only has GET handling. Fortunately in Lapis they work exactly the same way, and we can use the same route functions to render both requests. It works more or less like this:
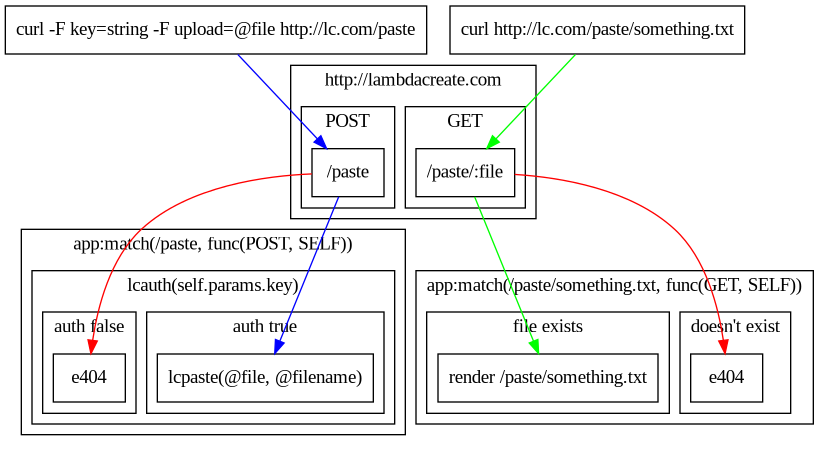
When you visit https://lambdacreate.com/paste/something.txt, Lapis drops into the GET specific function and returns a route to /paste/something.txt, internally this is just a static file serve and directs to /static/paste/something.txt. Once something is pasted it's up there and accessible. I don't currently have an archive of pasted things, but I'm considering adding a paste type to the archive routing. Otherwise GET for /paste is boring, it's dead simple nginx static file serving.
All the real magic happens in the POST function. When you POST to lambdacreate.com/paste it checks for the existence of a few values, first and foremost an authorization key. If that key is supplied and matches a good one in the database, then the actual lcpaste function is invoked and it pulls the file and the name of the file from self.params. Once the file is "pasted" a /paste/filename url is returned and you can view the file there. Otherwise if the key is bad, it returns an e404 and a Not Authorized message to the user, and nothing gets written to the site.
I'm pretty excited about this new feature, it should mean that I'll be able to paste to lambdacreate from any of my devices all with their own unique key. If I ever need to remove authorization for a device then it becomes a simple matter of removing the authorization info from the database. Obviously there's nothing unique about that, but I like knowing that I can control when and if things get pasted while still being able to generally route any requests to those pasted files.
Fin
Whew! I think that's about it! This has taken a little bit to get going, according to git I pushed the first commit in the series of these changes on May 18th, so about a month and a half of on and off work in mostly 1-2hr sessions to get this together. Feels really good since this has been something I've had to my TODO since I launched the blog a couple of years ago. Honestly rebuilding those docker containers got old fast. If you've read to the end thanks for sticking with me!
If you're curious about Lapis and want to try it out, Leafo has some pretty amazing documentation here, and I encourage you to take a look at Karai17's Lapischan, both of these are excellent resources for learning what Lapis can really do.